Vorbemerkung
Die zentrale Aufgabe der Webpräsenz ist eine dauerhaft gut zugängliche und intuitiv benutzbare Oberfläche für die Darstellung der Editionsbände. Dabei richtet sich die Publikation einerseits an ein (germanistisches sowie interdisziplinäres) Fachpublikum, soll aber gleichzeitig auch interessierten Laien und der breiteren Öffentlichkeit einen Zugang zum Forschungsgebiet ermöglichen. Ziel ist dabei vor allem, einfache und übersichtliche Zugänge zu den einzelnen Editionstexten zu gewährleisten, sowie weiterführende Informationen zum Thema zu bieten. Die Opitz-Webseite versteht sich damit als Arbeitsmittel für die germanistische Forschung und als Portal. Die nachstehenden Anmerkungen zur technischen Umsetzung beziehen sich zum einen auf die Be- bzw. Verarbeitung der XML-Daten, zum anderen auf deren Darstellung auf der Webseite.
Hinweise zur technischen Umsetzung:
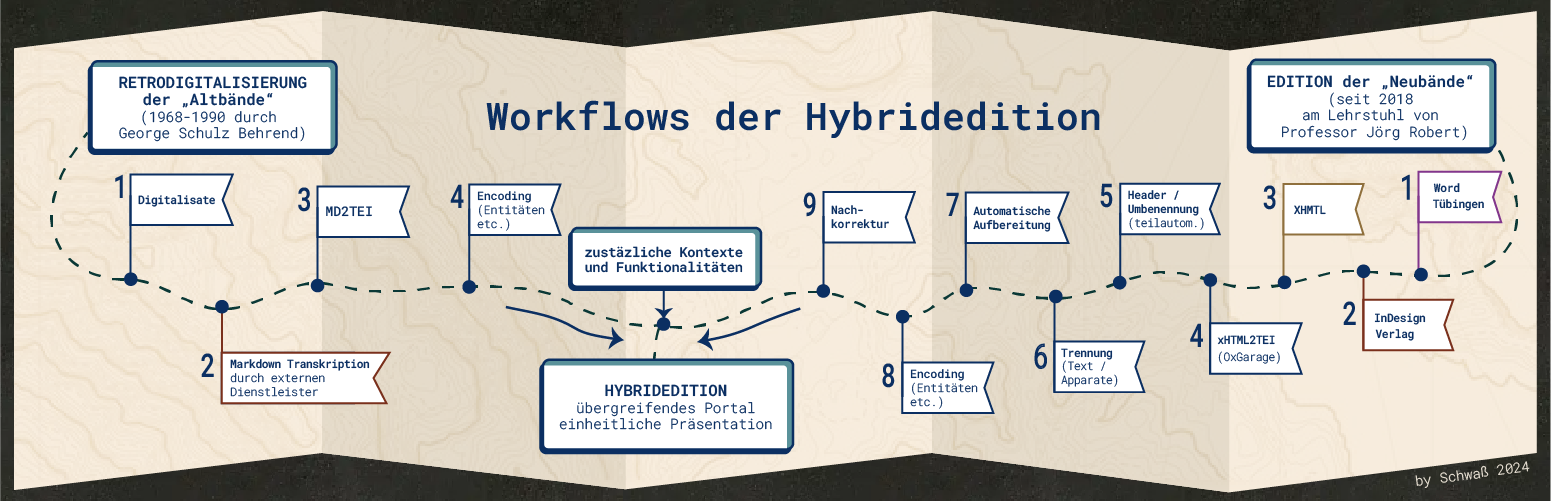
Workflows der Transkription in den Editionsbänden
Das Portal der Martin Opitz Hybridedition bildet sowohl die retro-digitalisierten und digital aufbereiteten Altbände der Schulz-Behrend Ausgabe (1968-1990), als auch die Neubände (seit 2018) ab, welche aktuell am Lehrstuhl für Literaturgeschichte der Frühen Neuzeit der Universität Tübingen entstehen und die Schulz-Behrend-Ausgabe um noch fehlende Texte aus Opitz‘ letzten Lebensjahren sowie posthum erschienenen Ausgaben erweitern sollen.
Dafür wurden die Bände I-IV der Schulz-Behrend Ausgabe in Wolfenbüttel zunächst imagedigitalisiert. Anschließend wurde der Text durch einen externen Dienstleister im Double-Keying Verfahren mittels Markdown volltexttranskribiert. Das Markdown wurde in valides TEI/XML transformiert und händisch weiter ausgezeichnet. Dabei orientierte man sich an den Vorgaben des Basisformats des Deutschen Textarchivs (DTABf).
Aufgrund mehrerer Datenformate und umfangreicher händischer Nachbereitung, gestaltet sich die Integration der neuen Editionsbände ab Band V verteilter und ist somit insgesamt komplexer. Die neuen Bände werden ebenfalls für die Online-Präsentation vorbereitet und in Absprache mit dem Hiersemann Verlag nach einer Moving Wall von 2 Jahren nach Veröffentlichung der Print-Publikation auf den Opitz Portal verfügbar sein.
Browser
Die Webseite sollte fehlerfrei auf den jeweils aktuellen Versionen aller gängigen Browser wie Mozilla Firefox, Internet Explorer, Microsoft Edge, Google Chrome, Safari und Opera funktionieren.
Transkription
Die retrodigitalisierte Version der historisch-kritischen Schulz-Behrend-Ausgabe folgt weitestgehend dem Layout des gedruckten Buches und ist online in der Wolfenbütteler Digitalen Bibliothek vollständig verfügbar. Grundsätzlich gilt es, den Text in Schriftzeichen und Layout so originalgetreu wie möglich wiederzugeben.
Bibliographie des Datensatzes
Die Metadaten des Datensatzes werden im teiHeader der jeweiligen Editionsdatei kodiert. Das fileDesc-Element erfasst dabei die einzelnen bibliographischen Daten.
<TEI>
<teiHeader>
<fileDesc>
...
</fileDesc>
</teiHeader>
</TEI>
Autor und Bandnummer
Zentrale Angaben zum Editionsband werden im title statement (<titleStmt>) aufgeführt. Hier finden sich zum Beispiel die Bandnummer des jeweiligen Editionstextes und dessen Autor*in samt deren Eintrag in der Gemeinsamen Normdatei (GND) der Deutschen Nationalbibliothek.
<titleStmt>
<title type="main">Martin Opitz. Gesammelte Werke</title>
<title type="sub">Band IV</title>
<title type="volume" n="1">Band IV</title>
<author>
<persName ref="http://d-nb.info/gnd/118590111">
<surname>Opitz</surname>
<forename>Martin</forename>
</persName>
</author>
...
</titleStmt>
Personen, Organisationen und Verantwortlichkeiten
Außerdem finden sich unter dem Unterpunkt des sogenannten statement of responsibility (<respStmt>) die verschiedenen Bearbeiter*innen der Quelle und deren genaue Verantwortlichkeiten. Dabei kann es sich um Organisationen (<orgName>) oder einzelne Personen (<persName>) handeln.
<titleStmt>
...
<respStmt>
<persName>
<surname>Nachname</surname>
<forename>Vorname</forename>
</persName>
<resp>
<note type="remarkResponsibility">Bearbeitung der digitalen Edition.</note>
</resp>
</respStmt>
...
<respStmt xml:id="textsource-1" corresp="#availability-textsource-1">
<orgName>Herzog August Bibliothek Wolfenbüttel</orgName>
<resp>
<note type="remarkResponsibility">Bereitstellung der Texttranskription.</note>
...
</resp>
</respStmt>
...
</titleStmt>
Publikation und Nutzungslizenzen
Das statement of publication (<publicationStmt>) liefert Informationen zur publizierenden Organisation oder Person (<publisher>), sowie der Verfügbarkeit (<availability>) und den Nutzungslizenzen (<licence>) der Text- und Bildquellen.
<publicationStmt>
<publisher>
<orgName role="project">Herzog August Bibliothek Wolfenbüttel</orgName>
<address>
<addrLine>Schlossplatz 1, 38304 Wolfenbüttel</addrLine>
<country>Germany</country>
</address>
</publisher>
<pubPlace>Wolfenbüttel</pubPlace>
<date type="publication">2019-03-27T13:33:54Z</date>
<availability xml:id="availability-textsource-1" corresp="#textsource-1">
<licence target="http://creativecommons.org/licenses/by-nc/3.0/de/">
<p>Distributed under the Creative Commons Attribution-NonCommercial 3.0 Unported
(German) License.</p>
</licence>
</availability>
</publicationStmt>
Hinweise zur Quelle und den Digitalisaten
In der source description (<sourceDesc>) wird die Quelle beschrieben, von der sich der elektronische Text ableitet. Das Element <biblFull> liefert bibliographische Angaben zur Quelle. Der manuscript identifier (<msIdentifier>) hilft bei der eindeutigen Identifizierung des jeweiligen Manuskripts, fasst die bestandshaltende Institution (<repository>) und verfügbare Imagedatei der Quelle.
<sourceDesc>
<biblFull>
...
</biblFull>
<msDesc xml:id="imagesource-1" corresp="#availability-imagesource-1">
<msIdentifier>
<repository>Herzog August Bibliothek Wolfenbüttel</repository>
<idno>
<idno type="shelfmark">68.1307</idno>
<idno type="URLCatalogue"
>http://diglib.hab.de/drucke/68-1307-1b/start.htm?image=00001</idno>
<idno type="URLImages"
>http://diglib.hab.de/drucke/68-1307-1b/start.htm?image=00001</idno>
</idno>
</msIdentifier>
</msDesc>
</sourceDesc>
Wortebene
Umlaute und Sonderzeichen
Umlaute und Sonderzeichen werden wie im Original wiedergegeben.
Abkürzungen
Abkürzungen werden wie im Original wiedergegeben und bleiben unaufgelöst.
Zahlen
Zahlen werden wie im Original wiedergegeben und nicht vereinheitlicht (Stimmt das noch???).
Sprache
Falls griechische Schrift vorkommt, wird sie nicht transkribiert, sondern die Stelle mithilfe der Angabe <foreign xml:lang="grk"/> gekennzeichnet.
Falls hebräische Schrift vorkommt, wird sie nicht transkribiert, sondern die Stelle mithilfe der Angabe <foreign xml:lang="hebr"/> gekennzeichnet.
Textstruktur
Der edierte Text eines Textträgers wird innerhalb der Elemente <text> und <body> codiert.
Textteile
Textabschnitte, die semantisch voneinander zu unterscheiden sind, werden durch div-Elemente gekennzeichnet. Dabei wird zwischen Einleitung ("preface"), Gedicht ("poem") und keiner Zuordnung unterschieden. Die Hauptkapitel werden im div-Element mit einer xml:id ausgezeichnet, welche identisch mit ihrer Kapitelnummer ist.
<text>
<body>
<div xml:id="I_8">
<div type="preface">
<div type="poem"> <lg> <l>Quis Pyladem nescit, cui notum nomen Orestis?</l> <l>Et quis Nüslerum, cui placet Opitius?</l> </lg> </div>
Absätze
Absätze werden durch p-Elemente markiert.
Seitenwechsel
Seitenwechsel werden am Anfang der physischen Seite mithilfe von <pb facs> wiedergegeben. Dabei stellen die Attribute facs die jeweilige Nummer der Imagedatei des Faksimiles, corresp den Link zur Imagedatei in der WDB und n die auf dem Seitenbild sichtbare Seitenzahl dar.
<pb facs="#xxxxx"
corresp="Link WDB"
n="yyy"/>
Zeilenangaben und Zeilenwechsel
Zeilenumbrüche werden durch ein <lb/> am Beginn der Zeile erfasst. Jede neue Zeile (auch nach Seitenumbruch) beginnt immer mit einem Zeilenumbruch. Gedichte und normale Texte sind außerdem mit einer Zeilenkodierung versehen. Bei Gedichten sind sie dabei mit <l n=““>, in normale Texte mit <lb n=““/> ausgezeichnet.
Trennzeichen innerhalb von Wörtern werden beibehalten; das getrennte Wort wird mit einem <w> umschlossen. Ist ein Wort am Seitenende getrennt, wird der pagebreak <pb> in das Wort eingesetzt und das Wort mit <w> gekennzeichnet.
<w>Wort-<pb facs="#xxxxx" corresp="Link WDB" n="yyy"/>trennung</w>
Marginalien
Marginalien werden so originalgetreu wie möglich wiedergegeben. Dabei bedeutet <note place="margin-left" text</note> , dass Marginalien links neben dem Haupttext und <note place="margin-right">text</note>, dass Marginalien rechts neben dem Hauptext stehen.
Fußnoten
Fußnoten werden mit <n>…</n> markiert und an der Stelle des Fußnotenzeichens in den Text eingefügt:
Text <n>Fußnotentext</n>
Textlayout
Überschriften
Durch das Layout erkennbare Überschriften – meistens durch Großbuchstaben, Großdruck, Fettdruck, Zentrierung oder andere typographische Besonderheiten abgesetzt – werden mit <head>…</head> markiert.
Illustrationen
Illustrationen werden mit <ill/> auf eigener Zeile markiert.
Nichtbildliche (abstrakte) Zierleisten, Balken und Linien werden übergangen; dasselbe gilt für kleine Zierstücke mit ornamentaler, figürlicher oder allegorischer Darstellung (Vignetten).
Tabellen
Tabellen mit <tab/> gekennzeichnet.
<table>
<row>
<cell>Eins</cell>
<cell>Zwei</cell>
</row>
<row>
<cell>Drei</cell>
<cell>Vier</cell>
</row>
</table>
Verspassagen
Durch das Layout erkennbare Verspassagen – typischerweise ein glatter oder regelmäßig versetzter linker Einzug, dabei aber nicht bis zum Zeilenende durchgeschriebener Text – oder allgemein rechtsbündige Textpassagen werden mit <l>...</l> markiert. Gedichte sind zusätzlich in Linegroups <lg> kodiert.
<lg rendition="#b">
<l>O Vater aller ding´ / vnd Herr der gantzen Welt/</l>
<l>Nim hin vnd führe mich wohin es dir gefellt;</l>
<l>Es ist kein säumniß hier; ich bin geschickt darzu</l>
<l>Vnd muß auch/ wann ich schon es nicht gar gerne thu.</l>
<l n="5">Du führst den der dir folgt/ vnd schleppst die widerstehn/</l>
<l>Vnd wann ich guet nicht wil/ so muß ich böse gehn. CF〉</l>
</lg>
Kustoden
Kustoden (Vorwegnahme des ersten Wortes der nächsten Seite in typographisch abgesetzter Schlusszeile), laufende oder feste Kopfzeilen und Blattzählungen (nicht zu verwechseln mit der durchlaufenden Seitenzählung) werden nicht erfasst.
Leerstellen
Im Druck auftretende Leerstellen und Virgeln (/) werden immer berücksichtigt.
Initialen
Ist der erste Buchstabe eines Textabschnitts besonders hervorgehoben (durch Übergröße bzw. Schmuckelemente; „Initiale“ genannt), wird er als Großbuchstabe in Normalgröße wiedergegeben; der unmittelbar folgende Buchstabe ist oft ein Großbuchstabe und wird dann auch so wiedergegeben.
Schriftschnitte
Besondere Schriftschnitte werden durch das Attribut @rendition ausgezeichnet.
Das Attribut kann dabei verschiedene Werte annehmen, zum Beispiel bei Kursivierungen (rendition="#i"), Fettmarkierungen (rendition="#b"), oder Unterstreichungen (rendition="#u").
Unsicherheiten
Unlesbarer Text
Unlesbarer Text wird mit „???“ wiedergegeben.
Erschließung und Kodierung von Normdaten
Für die Altbände (Band I-VI)
Im ersten Erarbeitungsschritt wurde die Normdatenerschließung für die drei Kategorien der Personen, Orte und Sachen durchgeführt. Hierzu wurden aus den Registern der Altbände eigene Listen erstellt und in diesen für die unterschiedlichen Objekten die xml: id vergeben. Für Personen, Orte und Sachen, die nicht identifizierbar waren, wurde ebenfalls ein Eintrag in den Listen vorgenommen und das Fehlen zusätzlich in einem Dokument notiert.
In einem zweiten Schritt wurden alle in den Listen angelegten Personen, Orte und Sachen anschließend in den Volltexten händisch ausgezeichnet. Bei Doppelnennung auf einer Seite wurden diese in den meisten Fällen lediglich einfach ausgezeichnet.
Für die Neubände (ab Band V)
Ein paar mehr Sätze dazu, wie wir bei den Neubänden vorgegangen sind???
Genannte Personen
In den Editionstexten genannte Personen sind in den einzelnen Textdateien mit <persName> ausgezeichnet. Das ref-Attribut an dieser Stelle verweist auf den Dateipfad des jeweiligen Registereintrags.
<persName ref="http://diglib.hab.de/edoc/ed000257/texts/register/listPerson.xml#geisler_anna_maria">Geisler</persName>
Im Personenregister werden für die Personen eindeutige Identifikatoren über das Attribut xml:id vergeben. Falls ein Eintrag zu der Person in der Gemeinsamen Normdatei (GND) der Deutschen Nationalbibliothek vorhanden ist, wird darauf diesen in einem ref-Attribut verwiesen. Liegt kein GND-Link vor, wird falls vorhanden, ein Wikipedia-Link hinterlegt oder eine Notiz aus der Printversion der Edition über die Charaktere angefertigt.
<person xml:id="geisler_anna_maria">
<persName ref="http://d-nb.info/gnd/1056165782">
<surname>Geisler</surname>
<forename>Anna</forename>
<forename>Maria</forename>
</persName>
<persName>
<name type="display">Geisler, Anna Maria</name>
</persName>
<linkGrp>
<ptr target="I_33"/>
<ptr target="II_1_48"/>
<ptr target="II_1_59"/>
<ptr target="IV_2_115"/>
</linkGrp>
</person>
Genannte Orte
In den Editionstexten erwähnte Orte sind in den einzelnen Textdateien mit <placeName> ausgezeichnet. Das ref-Attribut an dieser Stelle verweist auf den Dateipfad des jeweiligen Registereintrags.
<placeName ref="http://diglib.hab.de/edoc/ed000257/texts/register/listPlace.xml#oels">Olsnae</placeName>
Im Ortsregister werden für die Orte eindeutige Identifikatoren über das Attribut xml:id vergeben. Wenn für die topografischen Objekte bereits einen Eintrag in der geografischen Datenbank GeoNames vorhanden ist, wird auf diese verwiesen. Dabei werden nach den TEI-Richtlinien Verweise auf Orte (Siedlungen, Regionen, Nation) mithilfe des Elements <placeName>, geografische Merkmale (Inseln, Flüsse, Berge) mit <geogName> identifiziert.
<place xml:id="donau">
<geogName ref="http://www.geonames.org/791630/danube-river.html"
>Donau</geogName>
<geogName ref="http://www.geonames.org/791630/danube-river.html"
>Thonaw</geogName>
<linkGrp>
<ptr target="I_45"/>
<ptr target="IV_76A"/>
<ptr target="V_135c"/>
</linkGrp>
</place>
Sachen
Für die Sachen wurden keine Verlinkungen zu Normdatenbanken, sondern lediglich kurze Beschreibungen angelegt. Im Text werden Sachen mit dem Befehl <ref type =“sache“> und der Link zur Sachliste mit target ausgezeichnet. Bisher wurde allerdings auf dem Opitz Portal keine einzelne Register-Seite für Sachen angelegt.
<ref type="sache" target="http://diglib.hab.de/edoc/ed000257/texts/register/listsache.xml#petrodova">Petrodova</ref>
<item xml:id="petrodova">Petrodova<note>Ruine einer dakischen Stadt</note></note></item>
Datumsangaben + Genannte Werke
Datumsangaben und genannte Werke wurden nicht ausgezeichnet und mit Normdatenbanken verknüpft.
Apparateinträge
Die Umsetzung der Editionsrichtlinien für die Präsentation im Rahmen der digitalen Edition orientiert sich basal an den Vorgaben des Basisformats des Deutschen Textarchivs (DTABf), weicht aber in Einzelheiten von diesem ab, um den Spezifika des Materials gerecht zu werden. So ist es aktuell nicht möglich, mit dem DTABf Apparate funktional zu kodieren, da dieses eher auf die Abbildung des Seitenlayouts abzielt.